Learning a Strategy to Predict Stock Price
Machine Learning, Python
Github repo: https://github.com/AdarshGouda/Stock-Price-Prediction
- INTRODUCTION
The objective explored in this article is to implement two strategies leveraging the historical stock prices and generating trading signals. One of the strategies is a Manual Strategy where the rules of trading signals are predetermined while the other strategy, called Strategy Learner, uses Artificial Intelligence(AI) method to learn the rules and generate trade signals. In the scope of this article, BagLearner with RTLearner is the choice of AI method to learn the trading rules.
2. INDICATOR OVERVIEW
The following indicators are considered to generate BUY and SELL signals.
2.1 Simple Moving Average
A Simple Moving Average(SMA) indicator, as the name suggests, averages a range of prices over a chosen look-back period in that price range. In this paper, adjusted closing prices are used for calculating SMA.


SMAs can be used to compute Price-over-SMA Ratio(PSR) indicator which is basically an oscillator. This is computed as seen in Eqn-2. PSR indicator oscillates between +0.5 and -0.5. If PSR is greater than zero it indicates that price will move downwards and hence should be shorted and when it’s below zero it’s time to go long.
2.2 Bollinger Bands
Bollinger Bands (BB) are overlay types of indicators that are very popular in several markets. They provide unique insights into price trends and volatility such as overbought and oversold levels, underlying trends, and breakout signals. BB comprises a central trend-line, which is simply the SMA for a look-back period n and is bound between an upper-BB and lower-BB trend lines that are 2 standard deviations apart from the SMA.

One popular strategy is, when the price crosses into the BB region from lower-BB, BUY. And, when it crosses into the BB region from upper-BB, SELL. The BB Indicator (BBI) computed as per the equation below is used in this paper. When BBI is closer to the +1 and -1 range then it typically indicates an opportunity for long or short.

2.3 Momentum
Momentum Indicator(\(MOM\)) is an oscillator and can be used to determine the strength or weakness of a ticker. It shows the rate of ascending or descent in price action. The steepness of the change in price between the current and the look-back price is the strength of momentum, either negative or positive. The Momentum Indicator presented in this paper oscillates between -0.5 and +0.5.

The momentum indicator is specifically useful because they identify trend reversal spots. These spots are, fundamentally, the divergence between price movement, and its momentum. This can be achieved by analyzing momentum with SMA. For example, when the price has strong momentum and it crosses over SMA, that could signal a trading opportunity. Positive momentum is a BUY opportunity and negative momentum is a SELL opportunity.

3. DATASET
The “JPM” ticker is considered.
In-Sample Period: January 1, 2008, to December 31, 2009
Out-of-sample Period: January 1, 2010, to December 31, 2011
Starting Cash: $\$$100,000
Allowable positions are 1000 shares long, 1000 shares short, and 0 shares.
Commission: $\$9.95$, Impact: $\$0.005$
4. MANUAL STRATEGY
The Manual Strategy for this project is built based on all the three indicators discussed above.
4.1 Interpreting Indicators for Trade Signals
The details of the strategy are shown in the table below. Depending on the on-hand shares (current position) and the strength of either of the indicators, a BUY or SELL signal is generated and the shares to be traded are either 1000 or 2000. The limits on PSR and BBI are heavily based on the idea of overbought and oversold conditions while MOM is used to identify the strength of trend reversals. If the conditions in Figure 1 are not satisfied, we maintain the current position.
9.95, impact = 0.005
4.2 Performance of Manual Strategy
Using the insights provided by the technical indicators, the Manual Strategy should be considerably better, especially on the Out of Sample data.
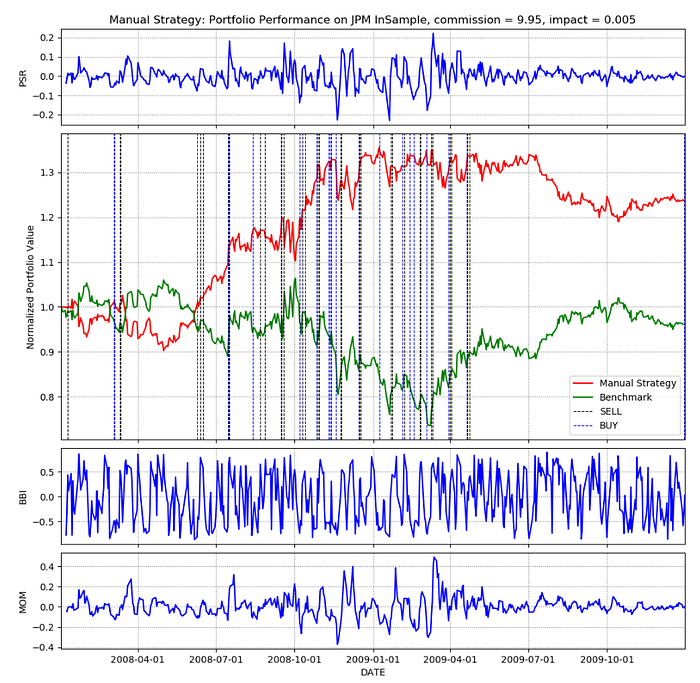
4.2.1 JPM In Sample Results
Code Execution in Terminal:
ManualStrategy.manual_vs_benchmark(symbol=”JPM”,sd=dt.datetime(2008, 1, 1), ed=dt.datetime(2009, 12, 31), lookback=5, sv=100000,type=”JPM InSample”, commission=9.95, impact=0.005)The lookback period of 5 is chosen to standardize between Manual Strategy and Strategy Learner. A lookback period of 5 yielded better performance of the Strategy Learner as will be seen in subsequent sections of this paper.
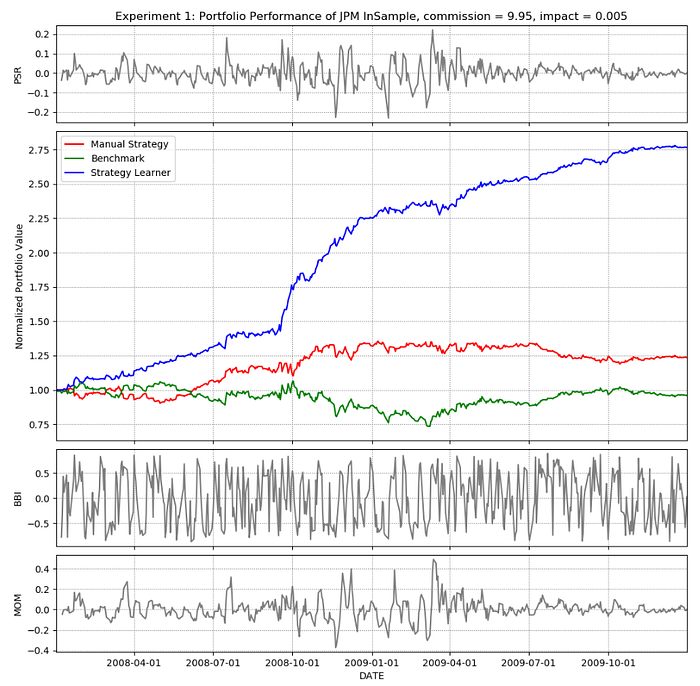
As seen in Figure 2, the Manual Strategy performed quite well on the “JPM” In Sample data with some underperformance at the beginning of the period.
4.2.2 JPM Out of Sample Results
Code Execution in Terminal:
ManualStrategy.manual_vs_benchmark(symbol=”JPM”,d=dt.datetime(2010, 1, 1), ed=dt.datetime(2011, 12, 31), lookback=5, sv=100000, type=”JPM outSample”, commission=9.95, impact=0.005)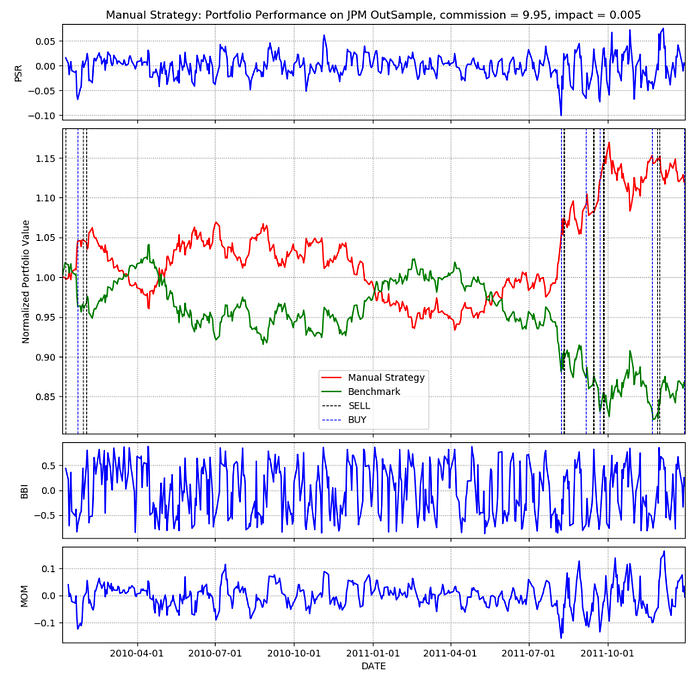
9.95, impact = 0.005
Seen in Figure 3 is the performance of Manual Strategy on the “JPM” Out of Sample data. Here too, the Manual Strategy outperforms the Benchmark.
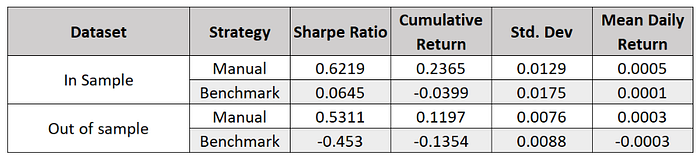
4.2.3 Metrics
It is evident from Figures 2, 3, and the metrics that the Manual Strategy outperforms Benchmark in both In Sample and Out of Sample datasets for JPM. The Manual Strategy has better average returns with lower volatility.
5. STRATEGY LEARNER
With the Strategy Learner, the trading problem is converted into a learning problem. The In Sample data is used for training the learner and the Out of Sample data is then used to test the learners' performance.
The learner I have used here is an ensemble learner which uses Bagging on Random Tree Learner. The problem is a classification problem to determine actions BUY, SELL, or HOLD. For ease of implementation, the actions are modified to +1, -1, and 0 respectively.
5.1 Method
5.1.1 Setup
The Strategy Learner instantiates BagLearner to create 25 Bags with leaf size =5. The BagLearner in turn instantiates RTLearner. Since the Bag size is 25, 25 Random Trees are created.
5.1.2 Data Treatment
I have used Ensemble learner which does not require the data to be discredited. However, if Q-Learning was chosen, the data would have to be discretized to formulate (state, action, reward, next-state) tuple.
5.1.3 Training
The add_evidence() method uses util.py to read in-sample data. The output from technical indicators is calculated using indicator.py. The data from the indicators are then combined to construct the xTrain data frame. A market variance of 2% is considered to generate yTrain labels.
5.1.4 Hyper-parameter Tuning
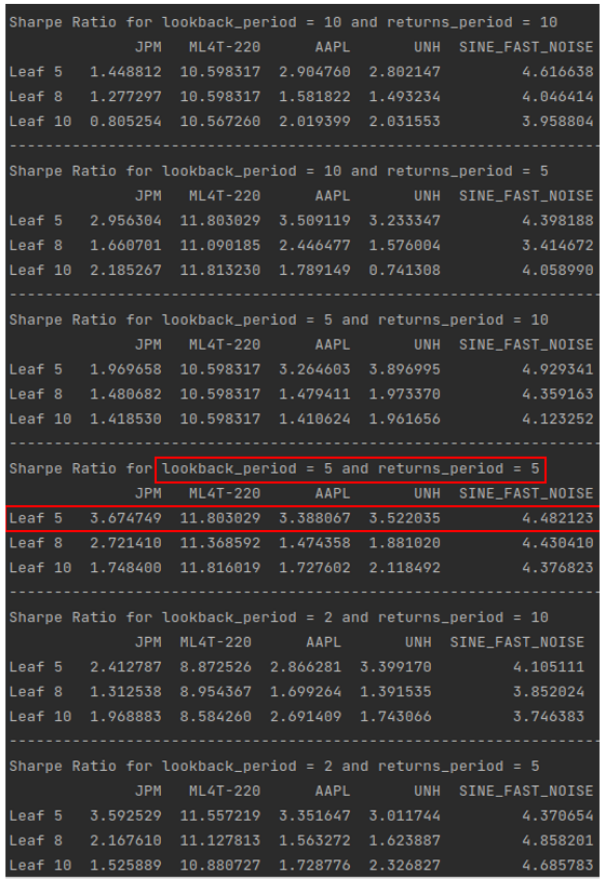
To find the best combination of Leaf_Size, the lookback period for indicators, and the n-day return period for calculating returns, I created a Grid Search with lookback periods of 10, 5, and 2 days with n-day return days of 10 and 5. Also, the Leaf sizes tried out were 5, 8, and 10. From Figure 5, based on the Sharpe ratio on In-Sample data of tickers JPM, ML4T-220, AAPL, UNH, and SINE_FAST_NOISE, leaf size of 5, lookback period of 5, and n-return period of 5 days were chosen. This grid search is implemented in optimize.py
5.1.5 Testing
The Out of Sample data is read using util.py in testPolicy() method. Then the same approach as Training is used to construct xTest data frame. To generate the yTest labels we call the query() method of the BagLearner. Once we have the labels, the trades are determined which can be between -2000 to +2000.
impact = 0.005
6. EXPERIMENT 1
In this experiment, Manual Strategy, Benchmark, and Strategy Learner are compared. In experiment1.py, I have implemented the get_port_stats() function to compute portfolio metrics which will be used to compare the strategies. The Manual Strategy works the same way mentioned in the above section to determine trading signal whereas the Strategy Learner uses AI techniques to learn the strategy. A seed value of 222579 is set to reproduce the same results each time the experiment1.py is run.
Hypothesis:
Strategy Learner will outperform both Manual Strategy and the Benchmark
Code Execution in Terminal:
experiment1.experiment1(symbol=”JPM”, sd=dt.datetime(2008, 1, 1), ed=dt.datetime(2009, 12, 31), lookback=5, sv=100000, type=”JPM inSample”, commission=9.95, impact=0.005, nReturns=5)
impact = 0.005
From the plot and table in Figure 6 and Figure 7, it is clear that the Strategy Learner outperforms Manual Strategy which in turn outperforms Benchmark. And as anticipated, the volatility is also lowest for the Strategy Learner
Consistency in performance: It is expected that Strategy learners will outperform Manual and Benchmark Strategies most of the time. Since the Strategy Learner uses RTLearner, there is inherent randomness in creating the Tree which can lead to an under-performing model. Even with this limitation, the Strategy Learner will mostly outperform Benchmark and Manual Strategy.
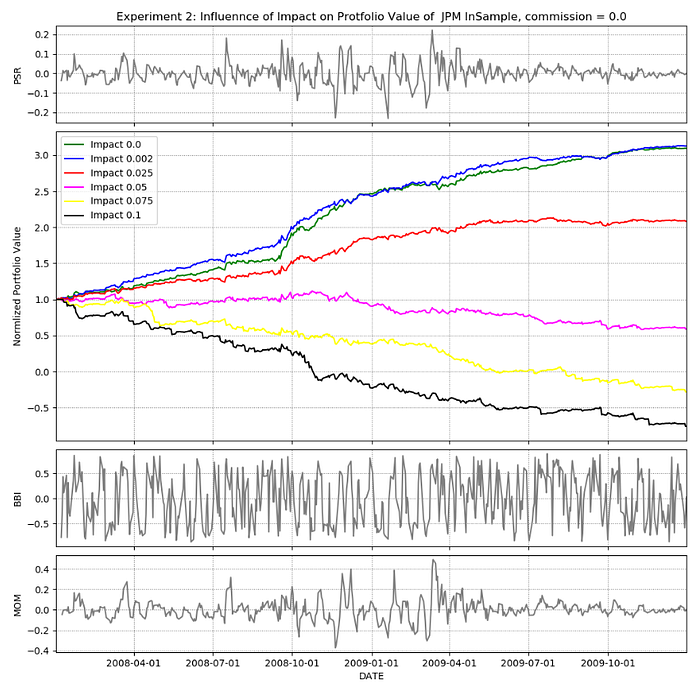
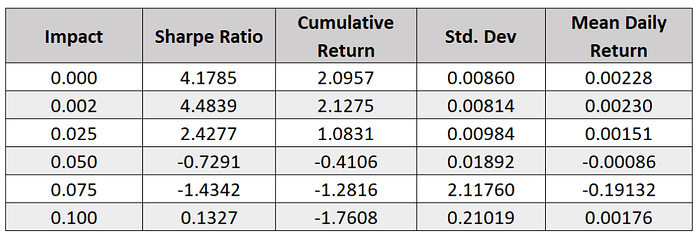
7. EXPERIMENT 2
The requirement of this experiment is to characterize the influence of “Impact” on the performance of Strategy Learner. The code for implementing this experiment is available in experiment2.py
Hypothesis:
The impact is the extent to which the price moves against the trader for executing a BUY or SELL. This implies, that a lower impact is always beneficial to the trader. Therefore, as the value of impact increases, the performance of the Strategy Learner deteriorates.
experiment2.experiment2(symbol=”JPM”, sd=dt.datetime(2008, 1, 1), ed=dt.datetime(2009,12, 31), lookback=5, sv=100000, type=”JPM inSample”, commission=9.95, nReturns=5)From the Plot and Table in Figures 8 and 9, it can be clearly seen that as the value of impact increases the performance of the Strategy Learner reduces thus supporting the Hypothesis.